Congestion Control
A Central Bank typically monitors various factors like money supply, inflation, economic growth rate and unemployment rate. Based on these factors it takes a decision if the economy is overheating, overcooling or just right. If the Central Bank thinks that the economy is overheating it raises interest rates to curb spending by consumers. The increase in rates has the impact of slowing the economy but the actual changes lag the action by months. For this reason, Central Banks space the interest rate reviews by at least a few months. Subsequent reviews can result in further raising (if the economy is still too hot) or lowering (if the economy has cooled more than expected) of rates. The Bank may leave the interest rates unchanged if it thinks that the economy is doing just fine.
You must be wondering why we are talking about Central Bank here. We have taken the example of Central Bank because congestion control also works on the same principle. The following paragraph describes the basic strategy involved in congestion control.
A congestion control system typically monitors various factors like CPU occupancy, link occupancy and messaging delay. Based on these factors it takes a decision if the system is overloaded. If the system is overloaded, it initiates actions to reduce the load by asking front end processors to reject traffic. The throttling of traffic will reduce the load but it there will be a certain time delay before which the monitored variables like CPU and Link occupancy show downward trend. Congestion control systems are designed to take this into account by spacing out congestion control actions. If the system continues to be overloaded, subsequent congestion control actions can further increase the traffic throttling. If the traffic load is just right, the system maintains current traffic throttling actions. If the system gets under loaded, the traffic throttling is reduced.
Congestion Control Basics
A system is said to be congested if it is being offered more traffic than its rated capacity. Most of the time, the system overload is due to too many active users. System maintenance and repair actions can also lead to system congestion. Whatever be the cause of overload, it will manifest as depletion of resources that are critical to the operation of the system. These resources can be CPU, free buffers, link bandwidth etc. Resource crunch will lead to lengthening of various queues for these resources. Due to lengthening of queues the response time of the system to external events will increase beyond permissible limits.
Impact of Overload on System Performance
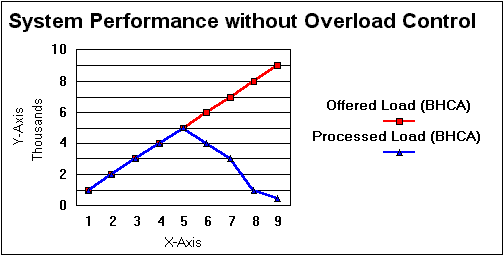
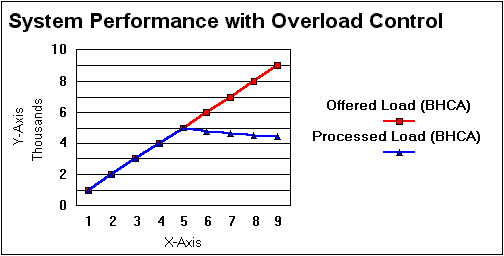
Increase in response time will lead to application level timeouts. This will further worsen the situation because applications will needlessly resend messages on timeouts, causing further congestion. If this condition continues the system might reach a condition where it can service no users. Thus in absence of any congestion control, the system will perform much below its rated capacity, leave alone handling the excess traffic. Refer to the figures below for a comparison of systems load handling capability with and without congestion control. (The system load is represented in Busy Hour Call Attempts, i.e. BHCA. The system has a rated capacity of 5000 BHCA).
Congestion Control Mechanism
The main objective of congestion control is to keep the system running pretty close to its rated capacity, even when faced with extreme overload. This is achieved by restricting users that are allowed service. The idea is to give satisfactory service to a small percentage of users rather than give highly degraded service to all the users. The users that were given service will leave the system after completion of service. This will reduce the load on the system. Now a different set of users can be given service. Thus in a phased manner, all users will get some service from the system.
An important requirement for the above mentioned scheme to work is that user blocking be done by the system should not overload main processors in the system. This is achieved by asking front end processors in the system to block the excess traffic. Thus the main processors do not even see the rejected traffic. They have to work only on the traffic that has been accepted, thus the main processors will be able to handle traffic pretty close to the rated capacity (See the graph above).
Congestion Control Triggers
Overload in a system can be detected by monitoring the CPU idle time and the length of various queues in the system. The CPU idle time is a very good measure of the traffic being handled by the CPU. It has been observed that CPU idle time decreases in direct proportion to the traffic being offered to the processor. Congestion of other resources in the system can be monitored by checking the length of the queue for the entities waiting for it. For example, monitoring the transmit queue length for a link gives a good idea of loading of the link. The receive queue length for a link gives a good idea of loading of the processor, as lengthening of this queue signifies that the processor receiving the message does not have enough time to process it.
CPU Congestion triggers are generated when the CPU idle time falls below a certain threshold. Link congestion triggers are generated when transmit queue length exceeds a predetermined threshold.
Congestion Control Example
In this section we will give a brief description of congestion control in a telephone exchange.
- The CPU idle time on the main processor in the exchange falls below 30%.
- CPU congestion trigger is reported to the overload control task.
- The overload control task asks the front end processors to block calls in 1 : 8 ratio, i.e. one out of every eight calls will be dropped by the front end processors.
- Dropping of calls will ease the load on the main processor. This might lead to CPU congestion abatement triggers being received by the overload control task (CPU idle time is 40%).
- The overload control task maintains the 1 : 8 blocking as it recognizes that reduction in CPU load is an affect of the currently applied call blocking.
- When the busy hour passes, call traffic would go down but the system is still blocking calls. This will result in yet another trigger reporting further rise in CPU idle time to 50%.
- At this point overload control task figures out that 1 : 8 call blocking is probably unnecessary. Thus it asks the front end processors to stop 1 : 8 blocking.
- Now the CPU idle time might measure 60%, but this is below the congestion onset threshold, so no further action is taken.
The timing of overload control action is extremely important. If overload control is introduced too soon the exchange would be rejecting traffic that it could have handled without any problems. On the other hand, if congestion control is delayed too long, the exchange might crash due to heavy traffic.